The Datakit plugin provides the following node types:
|
Node type
|
Description
|
Inputs
|
Outputs
|
Branch (branch) v3.12+
|
Execute different nodes based on matching input conditions.
|
User-defined.
The input to a branch node represents a boolean condition to test and branch on:
- If the input is
true, the nodes named by the then array are executed
- If the input is
false, the nodes named by the else array are executed
- If the input is a non-boolean value, an error is raised
|
none
|
Cache (cache) v3.12+
|
Store and fetch cached data.
|
-
key (required): The cache key string
-
ttl: The TTL (Time to Live) in seconds
-
data: The data to be cached. If not null, the cache node works in set mode storing data into cache; if null, the cache node fetches data.
|
-
hit: true if a cache hit occurred
-
miss: true if a cache miss occurred
-
stored: true if data was successfully stored into the cache
-
data: The data that was stored into the cache
|
Call (call)
|
Send third-party HTTP calls.
|
-
body: Request body
-
headers: Request headers
-
query: Key-value pairs to encode as the request query string
-
url: The request URL resolved at runtime
-
https_proxy: The HTTPS proxy URL to use for the request
-
http_proxy: The HTTP proxy URL to use for the request
-
proxy_auth_username: The username to authenticate with the proxy
-
proxy_auth_password: The password to authenticate with the proxy
|
-
body: The response body
-
headers: The response headers
-
status: The HTTP status code of the response
|
jq (jq)
|
Transform data and cast variables with jq to be shared with other nodes.
|
User-defined. See jq node inputs for more detail.
|
User-defined. See jq node outputs for more detail.
|
Exit (exit)
|
Return directly to the client without forwarding any further.
|
-
body: Body to use in the early-exit response.
-
headers: Headers to use in the early-exit response.
|
None
|
Property (property)
|
Get and set Kong Gateway-specific data.
|
Accepts $self. See property node inputs for more detail.
|
Outputs $self. See property node outputs for more detail.
|
Static (static)
|
Configure static input values ahead of time.
|
None
|
User-defined. See static node outputs for more detail.
|
XML to JSON (xml_to_json) v3.13+
|
Transforms XML strings into JSON or a Lua table.
|
XML formatted data
|
JSON formatted data
|
JSON to XML (json_to_xml) v3.13+
|
Transforms JSON or a Lua table into XML strings.
|
JSON formatted data or Lua tables
|
XML formatted data
|
You can learn more about the supported configuration parameters for each node in the configuration reference.
Execute different nodes based on matching input conditions, such as a cache hit or miss.
See the configuration reference and select branch from the node object dropdown to see all node attributes, including inputs and outputs.
Note: When using the branch node, the then and else parameters must list all nodes for both branches.
If a node isn’t listed in the branch, the node will run depending on its location in the flow configuration.
The following example configuration takes the input of a cache node named GET:
- If it sees a
miss, it executes the nodes DATA, SET, and EXIT_MISS.
- If it doesn’t see a
miss, it executes the node EXIT_HIT.
Cache input:
- type: static
values:
key: cache key
name: CACHE_KEY_GET
- type: cache
input: CACHE_KEY_GET
ttl: 200
name: GET
Branch node based on cache hit or miss:
- type: branch
then:
- DATA
- SET
- EXIT_MISS
else:
- EXIT_HIT
input: GET.miss
name: branch
See Conditionally fetching or storing cache data for a full example.
Store data into a cache and fetch cached data from a cache.
See the configuration reference and select cache from the node object dropdown to see all node attributes.
The cache node requires a resources.cache resource definition containing
cache configuration.
For a complete example, see:
Send an HTTP request and retrieve the response.
v3.13+ The call node can be executed before or after proxying a request.
For versions of Kong Gateway 3.12 or earlier, call nodes could only be executed before proxying; see limitations for details.
See the configuration reference and select call from the node object dropdown to see all node attributes.
Make an external API call:
- name: CALL
type: call
url: https://example.com/foo
Send a POST request with a JSON body:
- name: POST
type: call
url: https://example.com/create-entity
method: POST
inputs:
body: ENTITY
- name: ENTITY
type: static
values:
id: 123
name: Datakit
Perform a request through a proxy server:
- name: CALL
type: call
url: https://example.com/foo
inputs:
https_proxy: http://my-proxy.example.com:8080
proxy_auth_username: my-username
proxy_auth_password: my-password
Call nodes are used in most datakit workflows. For complete examples, see:
If the data connected to the body input is an object, it will automatically be
encoded as JSON, and the request Content-Type header will be set to
application/json unless already present in the headers input.
Similarly, if the response Content-Type header matches the JSON mime-type, the
body output will be JSON-decoded automatically.
This is an async node. This means that the request will be sent in the
background while Datakit executes any other nodes (save for any nodes which
depend on it). Multiple call nodes are executed concurrently when no dependency
order enforces it.
In this example, both CALL_FOO and CALL_BAR will be started as soon as
possible, and then Datakit will block until both have finished to run
JOIN:
- name: CALL_FOO
type: call
url: https://example.com/foo
- name: CALL_BAR
type: call
url: https://example.com/bar
- name: JOIN
type: jq
jq: "."
inputs:
foo: CALL_FOO.body
bar: CALL_BAR.body
The call node fails execution if a network-level error is encountered or if
the endpoint returns a non-2xx status code. It will also fail if the endpoint
returns a JSON mime-type in the Content-Type header if the response body is
not valid JSON.
A call node defines its url statically during configuration. To substitute a different endpoint at runtime, pass a value via the url input. If the input is nil, Datakit automatically reverts to the configured static URL.
For example:
- name: DYNAMIC_URL
type: call
url: https://example.com/default
inputs:
url: request.body
The call node supports performing requests via a proxy server. This is controlled by proxy options. See above example for more details.
Call node supports following content types for request body encoding:
application/jsonapplication/x-www-form-urlencoded
By default, if the body input is an object, it will be encoded as JSON. To override this behavior and use application/x-www-form-urlencoded, set the Content-Type header accordingly in the headers input for the call node.
See Third-party auth for an example of using application/x-www-form-urlencoded request body encoding.
In Kong Gateway 3.12 and earlier, the call node couldn’t be executed after proxying a
request, so attempting to configure the node using outputs from the upstream service
response would yield an error:
- name: CALL
type: call
url: https://example.com/
method: POST
inputs:
# dependency error!
body: service_response.body
Error:
invalid dependency (node #1 (CALL) -> node service_response): circular dependency
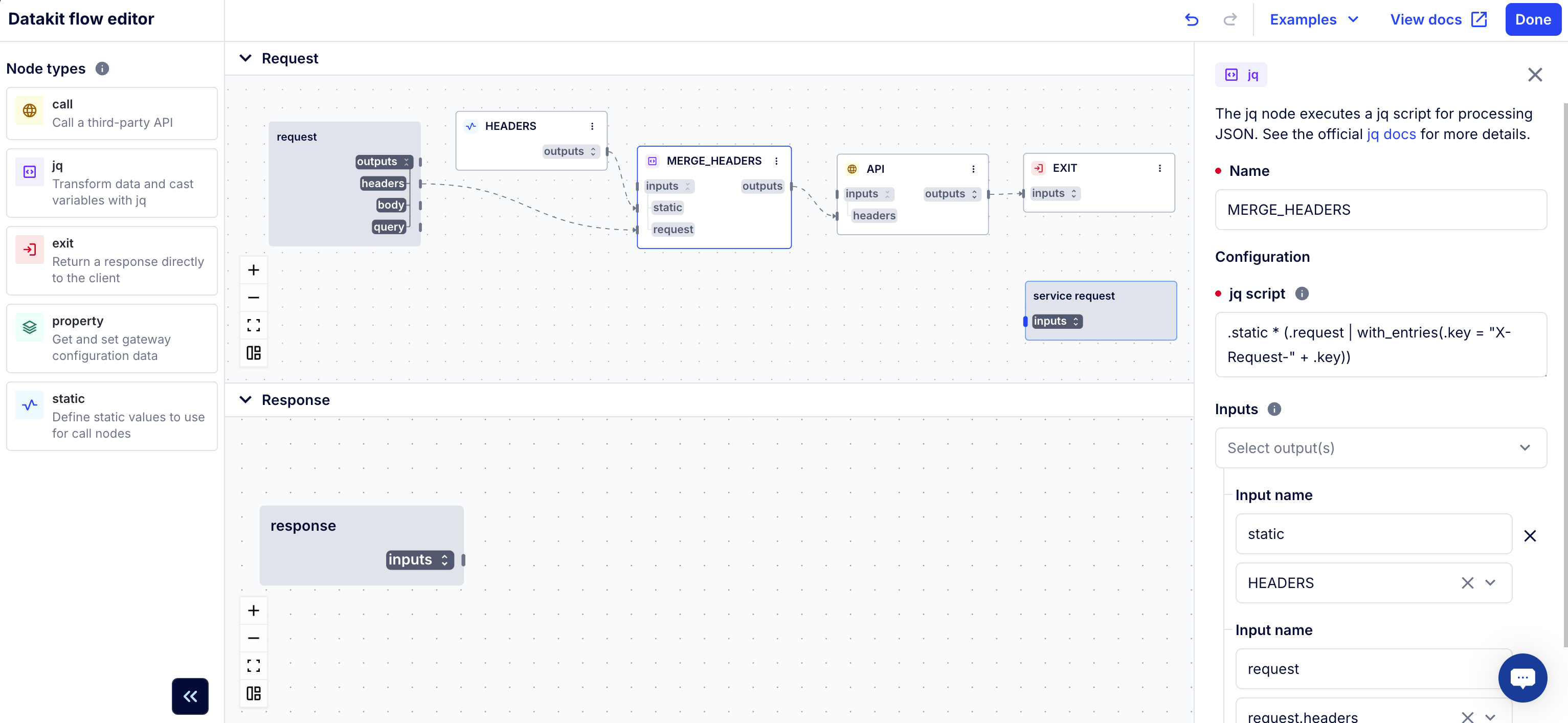
The jq node executes a jq script for processing JSON. See the official
jq docs for more details.
See the configuration reference and select jq from the node object dropdown to see all node attributes.
Inputs for the jq node are user-defined. For node-wise ($self) connections, jq can handle input of
any type:
- name: SERVICE
type: property
property: kong.router.service
- name: IP
type: property
property: kong.client.ip
- name: FILTER_SERVICE
type: jq
input: SERVICE
# yields: "object"
jq: ". | type"
- name: FILTER_IP
type: jq
input: IP
# yields: "string"
jq: ". | type"
By defining individual inputs, jq’s input will be coerced to an object with
string keys and values of any type. Referencing input fields from within the
filter is done by using dot (.) notation:
- name: SERVICE
type: property
property: kong.router.service
- name: IP
type: property
property: kong.client.ip
- name: FILTER_SERVICE_AND_IP
type: jq
inputs:
service: SERVICE
ip: IP
# yields: { "$self": "object", "service": "object", "ip": "string" }
jq: |
{
"$self": (. | type),
"service": (.service | type),
"ip": (.ip | type)
}
jq node outputs are user-defined. A jq filter script can produce any type of data:
- name: STRING
type: jq
jq: |
"my string"
- name: NUMBER
type: jq
jq: |
54321
- name: BOOLEAN
type: jq
jq: |
true
- name: OBJECT
type: jq
jq: |
{
a: 1,
b: 2
}
It’s impossible for Datakit to know ahead of time what kind of data jq will
emit, so Datakit uses runtime checks when the output of jq is connected to
another node’s input. It’s important to carefully test and validate your Datakit
configurations to avoid this case:
- name: HEADERS
type: jq
jq: |
"oops, not an object/map"
- name: EXIT
type: exit
inputs:
# this will cause Datakit to return a 500 error to the client when
# encountered
headers: HEADERS
This is also why the jq node doesn’t allow explicitly referencing individual
fields with outputs at config-time:
- name: HEADERS
type: jq
jq: |
"this is completely opaque to Datakit"
# Datakit will reject this configuration because it can't confirm that the
# output of HEADERS is an object or has a `body` field
outputs:
body: EXIT.body
- name: EXIT
type: exit
To enable a high level of transparency and compatibility when
communicating with external services, headers outputs in Datakit always
preserve the original case of header names. While HTTP-centric nodes within
Datakit are careful to account for this and perform header lookups and
transformations in a case-insensitive manner, jq at its core is a library for
operating upon JSON data, and JSON object keys are strictly case-sensitive.
Be mindful of this when handling headers in a jq filter to avoid buggy, error-prone behavior.
For example:
# adds the `X-Extra` header to the upstream service request if not set by the client
- name: ADD_HEADERS
type: jq
input: request.headers
output: service_request.headers
jq: |
{
"X-Extra": ( .["X-Extra"] // "default value" ),
}
This filter will function correctly if the client sets the X-Extra header or
omits it entirely, but it won’t have the intended effect if the client sets
the header X-EXTRA or x-extra.
jq lets you write a robust filter that handles this condition.
The following implementation normalizes header names to lowercase before looking up values from the input:
# adds the `X-Extra` header to the upstream service request if not set by the client
- name: ADD_HEADERS
type: jq
input: request.headers
output: service_request.headers
jq: |
with_entries(.key |= ascii_downcase)
| {
"X-Extra": ( .["x-extra"] // "default value" ),
}
These examples take in client request headers and update them from a set of
pre-defined values.
The HTTP specification RFC
defines header names to be case-insensitive, so in most cases it’s
enough to normalize header names to lowercase for ease of merging the
two objects:
- name: header_updates
type: static
values:
X-Foo: "123"
X-Custom: "my header"
X-Multi:
- "first"
- "second"
- name: merged_headers
type: jq
inputs:
original: request.headers
updates: header_updates
jq: |
(.original | with_entries(.key |= ascii_downcase))
*
(.updates | with_entries(.key |= ascii_downcase))
- name: api
type: call
url: "https://example.com/"
inputs:
headers: merged_headers
However, when dealing with a upstream service or API that isn’t fully compliant
with the HTTP spec, it might be necessary to preserve original header name
casing. For example:
- name: header_updates
type: static
values:
X-Foo: "123"
X-Custom: "my header"
X-Multi:
- "first"
- "second"
- name: merged_headers
type: jq
inputs:
original: request.headers
updates: header_updates
jq: |
. as $input
# store .original key names for lookup
| $input.original
| with_entries({ key: .key | ascii_downcase, value: .key })
as $keys
# rewrite .updates with .original key names
| $input.updates
| with_entries(.key = ($keys[.key | ascii_downcase] // .key))
as $updates
| $input.original * $updates
- name: api
type: call
url: "https://example.com/"
inputs:
headers: merged_headers
Coerce the client request body to an object:
- name: BODY
type: jq
input: request.body
jq: |
if type == "object" then
.
else
{ data: . }
end
Join the output of two API calls:
- name: FOO
type: call
url: https://example.com/foo
- name: BAR
type: call
url: https://example.com/bar
- name: JOIN
type: jq
inputs:
foo: FOO.body
bar: BAR.body
jq: "."
For more detailed examples, see:
Trigger an early exit that produces a direct response, rather than forwarding
a proxied response.
There are no outputs for an exit node.
See the configuration reference and select exit from the node object dropdown to see all node attributes.
Make an HTTP request and send the response directly to the client:
- name: CALL
type: call
url: https://example.com/
- name: EXIT
type: exit
input: CALL
For more detailed examples, see:
Get and set Kong Gateway host and request properties.
See the configuration reference and select property from the node object dropdown to see all node attributes.
Whether a get or set operation is performed depends upon the node inputs:
- If an input is connected,
set the property
- If no input is connected,
get the property and map it to the output
The property node accepts the $self input:
- name: STORE_REQUEST
type: property
property: kong.ctx.shared.my_request
input: request
No individual field-level inputs are permitted:
- name: STORE_REQUEST_BY_FIELD
type: property
property: kong.ctx.shared.my_request
# error! property input doesn't allow field access
inputs:
body: request.body
The property node produces the $self output.
- name: GET_ROUTE
type: property
property: kong.router.route
output: response.body
Field-level output connections are not supported, even if the output data has known fields:
- name: GET_ROUTE_ID
type: property
property: kong.router.route
# error! property output doesn't allow field access
outputs:
id: response.body
The following properties support get operations:
|
Property
|
Description
|
Data type
|
kong.client.consumer
|
kong.client.get_consumer()
|
object
|
kong.client.consumer_groups
|
kong.client.get_consumer_groups()
|
array
|
kong.client.credential
|
kong.client.get_credential()
|
object
|
kong.client.get_identity_realm_source
|
kong.client.get_identity_realm_source()
|
object
|
kong.client.forwarded_ip
|
kong.client.get_forwarded_ip()
|
string
|
kong.client.forwarded_port
|
kong.client.get_forwarded_port()
|
number
|
kong.client.ip
|
kong.client.get_ip()
|
string
|
kong.client.port
|
kong.client.get_port()
|
number
|
kong.client.protocol
|
kong.client.get_protocol()
|
string
|
kong.request.forwarded_host
|
kong.request.get_forwarded_host()
|
string
|
kong.request.forwarded_port
|
kong.request.get_forwarded_port()
|
number
|
kong.request.forwarded_scheme
|
kong.request.get_forwarded_scheme()
|
string
|
kong.request.port
|
kong.request.get_port()
|
number
|
kong.response.source
|
kong.response.get_source()
|
string
|
kong.router.route
|
kong.router.get_route()
|
object
|
kong.route_id
|
Gets the current Route’s ID
|
string
|
kong.route_name
|
Gets the current Route’s name
|
string
|
kong.router.service
|
kong.router.get_service()
|
object
|
kong.service_name
|
Gets the current Service’s name
|
string
|
kong.service_id
|
Gets the current Service’s ID
|
string
|
kong.service.response.status
|
kong.service.response.status
|
number
|
kong.version
|
Gets the Kong version
|
string
|
kong.node.id
|
kong.node.get_id()
|
string
|
kong.configuration.{key}
|
Reads {key} from the node configuration
|
any
|
The following properties support set operations:
|
Property
|
Description
|
Data type
|
kong.service.target
|
kong.service.set_target({host}, {port})
|
string ({host}:{port})
|
kong.service.request_scheme
|
kong.service.set_service_request_scheme({scheme})
|
string ({scheme})
|
The following properties support get and set operations:
|
Property
|
Description
|
Data type
|
kong.ctx.plugin.{key}
|
Gets or sets kong.ctx.plugin.{key}
|
any
|
kong.ctx.shared.{key}
|
Gets or sets kong.ctx.shared.{key}
|
any
|
Emits static values to be used as inputs for other nodes.
The static node can help you with hardcoding some known value for an input.
There are no inputs for a static node.
See the configuration reference and select static from the node object dropdown to see all node attributes.
This node produces outputs for each item in its values attribute:
- name: CALL_INPUTS
type: static
values:
headers:
X-Foo: "123"
X-Multi:
- first
- second
query:
a: true
b: 10
body:
data: "my request body data"
- name: CALL
type: call
url: https://example.com/
method: POST
input: CALL_INPUTS
The static nature of these values comes in handy, because Datakit can
validate them when creating or updating the plugin configuration. Attempting to
create a plugin with the following configuration will yield an Admin API
validation error instead of bubbling up at runtime:
- name: CALL_INPUTS
type: static
values:
headers: "oops not valid headers"
- name: CALL
type: call
url: https://example.com/
method: POST
input: CALL_INPUTS
Set a property from a static value:
- name: VALUE
type: static
values:
data:
a: 1
b: 2
- name: PROPERTY
type: property
property: kong.ctx.shared.my_property
input: VALUE.data
Set a default value for a jq filter:
- name: VALUE
type: static
values:
default: "my default value"
- name: FILTER
type: jq
inputs:
query: request.query
default: VALUE.default
jq: ".query.foo // .default"
Set common request headers for different API requests:
- name: HEADERS
type: static
values:
X-Common: "we always need this header"
- name: CALL_FOO
type: call
url: https://example.com/foo
inputs:
headers: HEADERS
- name: CALL_BAR
type: call
url: https://example.com/bar
inputs:
headers: HEADERS
For more detailed examples, see:
Transforms XML strings to JSON or a Lua table. Empty XML tags or elements are converted into empty JSON objects. The resulting JSON won’t preserve any information about the original XML element order.
See the configuration reference and select xml_to_json from the node object dropdown to see all node attributes.
Note: One of the attributes_block_name or attributes_name_prefix is required.
If provided the following XML:
<root>
<name>Alice</name>
<age>30</age>
<is_student>false</is_student>
<courses>Math</courses>
<courses>Science</courses>
<address>
<street>123 Main St</street>
<city>Wonderland</city>
</address>
<null_value>null</null_value>
</root>
The XML to JSON node will output the following JSON:
{
"root": {
"name": "Alice",
"age": 30,
"is_student": false,
"courses": ["Math", "Science"],
"address": {
"street": "123 Main St",
"city": "Wonderland"
},
"null_value": null
}
}
The configuration for the node would look like this:
- name: CONVERT_XML_TO_JSON
type: xml_to_json
root_element_name: root
attributes_block_name: "#attr"
input: CALL_FOO
Where CALL_FOO is a call node that calls an API, and that API outputs XML.
For a more detailed example, see Convert XML into JSON.
For an example of using this node as part of a workflow, see Transform JSON into XML and back.
Transforms JSON strings or Lua tables into XML. Empty string, empty array, and empty object values are converted into empty XML elements. The resulting XML won’t preserve any information about the original JSON object key order.
See the configuration reference and select json_to_xml from the node object dropdown to see all node attributes.
The order of elements in the generated XML is non-deterministic and must not be relied upon.
If provided the following JSON:
{
"root": {
"name": "Alice",
"age": 30,
"is_student": false,
"courses": ["Math", "Science"],
"address": {
"street": "123 Main St",
"city": "Wonderland"
},
"null_value": null
}
}
The JSON to XML node will output the following XML:
<root>
<name>Alice</name>
<age>30</age>
<is_student>false</is_student>
<courses>Math</courses>
<courses>Science</courses>
<address>
<street>123 Main St</street>
<city>Wonderland</city>
</address>
<null_value>null</null_value>
</root>
The configuration for the node would look like this:
- name: CONVERT_JSON_TO_XML
type: json_to_xml
root_element_name: root
attributes_block_name: "#attr"
input: CALL_BAR
Where CALL_BAR is a call node that calls an API, and that API outputs JSON.
For a more detailed example, see Convert JSON into XML.
For an example of using this node as part of a workflow, see Transform JSON into XML and back.
Datakit also defines a number of implicit nodes that can’t be declared directly under the nodes configuration section.
These nodes can either be used without being explicitly declared, or declared under the global resources object.
These reserved node names can’t be used for user-defined nodes. They include:
|
Node
|
Description
|
Inputs
|
Outputs
|
declaration
|
request
|
Reads incoming client request properties
|
none
|
body, headers, query
|
none
|
service_request
|
Updates properties of the request sent to the service being proxied to
|
body, headers, query
|
none
|
none
|
service_response
|
Reads response properties from the service being proxied to
|
none
|
body, headers
|
none
|
response
|
Updates properties of the outgoing client response
|
body, headers
|
none
|
none
|
vault
|
Vault reference to hold secret values
|
none
|
$self
|
resources.vault
|
The headers type produces and consumes maps from header names to their values:
- Keys are header names. Original header name casing is preserved for maximum
compatibility.
- Values are strings if there is a single instance of a header or arrays of
strings if there are multiple instances of the same header.
The query type produces and consumes maps with key-value pairs representing
decoded URL query strings.
The service_request.body and response.body inputs both accept any data type.
If the data is an object, it will automatically be JSON-encoded, and the
Content-Type header set to application/json (if not already set in the
headers input).
The request.body and service_response.body outputs have a similar behavior.
If the corresponding Content-Type header matches the JSON mime-type, the
body output is automatically JSON-decoded.
The vault node is an implicit node that allows you to declare secret references
and can be used in other nodes as a source of secret values. Vault references are declared
under the resources.vault configuration.
Declare two vault references and use them in a jq node:
resources:
vault:
secret1: "{vault://env/my-secret1}"
secret2: "{vault://aws/my-secret2}"
nodes:
- name: JQ
type: jq
inputs:
secret1: vault.secret1
secret2: vault.secret2
jq: "."